



|
|
|
|
Просмотрев в предыдущих главах множество алгоритмов текстового поиска, мы теперь перейдем к исследованию потенциальных путей решения исходной задачи. Сначала, однако, имеет смысл посмотреть, какое отношение имеет изучение этих алгоритмов к экспериментальной системе обработки информации, упоминавшийся в начале.
Обсуждаемая обрабатывающая система претендует на применение во многих различных областях, включая извлечение информации и распознавание приближенных образцов. Таким образом, при разработке данной системы уместно исследование эффективных методов извлечения подстрок текста. Например, алгоритм Бойера-Мура-Хорспула обеспечивает быстрый и легко реализуемый метод поиска заданной подстроки в тексте. Представление данных в виде суффиксного дерева (описанное в 4.4.2) здесь также полезно, так как оно позволяет эффективно проводить множественные поиски заданного текста. Кроме того, следует заметить, что эта структура позволяет выполнять последовательное сжатие данных за линейное время. (Предполагаемое функционирование нашей обрабатывающей системы основывается на принципе сжатия данных).
Алгоритмы поиска расстояния между строками и нечеткого сопоставления строк, безусловно, имеют отношение к распознаванию шаблонов, при котором требуется идентифицировать вхождения, отстоящие от заданного образца на определенное расстояние. Более того, особенно уместной является проделанная работа с произвольными символами, так как в этой системе предусматривается поддержка подобных символов. Особое отношение, как можно будет увидеть из следующего раздела, к этой задаче имеют алгоритмы самой длинной общей последовательности и самой длинной повторяющейся подстроки.
Родственная проблема, решение которой, между прочим, является целью системы, состоит в нахождении образцов, общих для произвольного числа входных строк. Это, по сути, является разновидностью задачи N-lcs. Поэтому интересно вспомнить, что, как мы видели, задача |N-lcs| является NP-полной [Maier, 1978].
В самом начале было сказано, что более естественным кажется использовать конечный алфавит, чем разрешать произвольные строки ASCII символов, представляющие атомарные символы. Как мы видели, использование конечного алфавита приводит к значительным упрощениям во многих приложениях текстового поиска. Например, это позволяет применять методы сопоставления типов Бойера-Мура.
Кроме того, в начале работы обсуждалось, чем является образец в задаче – подстрокой или подпоследовательностью. Для первого случая было показано, что задача решается с помощью методов суффиксных деревьев. Повторим, что самая длинная повторяющаяся подстрока может быть найдена за линейное время путем построения суффиксного дерева строки текста [McCreight, 1976], и максимальные повторения могут быть найдены из этого дерева за общее время O(n+r), где r – число найденных пар повторений [Baker, 1992]. Второй случай, а именно, повторяющиеся подпоследовательности, рассматривается ниже.
Первоначально утверждалось, что задача состоит в нахождении максимальных непересекающихся повторяющихся подпоследовательностей входной строки. Со временем было добавлено, что перекрывающиеся последовательности должны быть исключены. Описание одного из возможных подходов к решению этой ограниченной задачи приводится ниже, а затем следует обсуждение более эффективного подхода, который подходит также для неограниченной задачи.
Если второе вхождение максимальной повторяющейся подпоследовательности в строке y начинается с позиции i, то эта подпоследовательность может быть найдена вычислением наибольшей общей подпоследовательности y(1, i-1) и y(i, n). Таким образом, один из возможных подходов к решению этой задачи состоит в вычислении lcs(y(1, i-1), y(1, n)) для i = 2..n. Применение алгоритма lcs с квадратичным временем приведет к общему времени обработки O(n3). Использование алгоритма lcs со временем O(n2) дает границу для худшего случая практической реализации; средний случай, однако, может оказаться гораздо более благоприятным. Как мы уже видели, помимо требующих квадратичного времени алгоритмов lcs (например, Хиршберг [Hirschberg, 1975]), существуют и такие, которые демонстрируют гораздо более привлекательную среднюю эффективность. В качестве примеров упомянем алгоритм Ханта и Шиманского [Hunt, Szymanski, 1977], для которого среднее время равно O(n log n), его эффективность в худшем случае снижается до O(n2 log n), и метод Укконена [Ukkonen, 1983, 1985a] с средним временем O(nd) и квадратичным в худшем случае. Вспомним также, что алгоритм Машека и Патерсона [Masek, Paterson, 1980, 1983] является субквадратичным во всех случаях, что, однако, достигается ценой слишком большой константы пропорциональности.
При вышеуказанных ограничениях на подпоследовательности, перекрывающиеся вхождения максимальной повторяющейся подпоследовательности найти не удается. Ослабление этого ограничения, таким образом, означает, что мы должны также быть способны находить непересекающиеся вхождения максимальной повторяющейся подпоследовательности, перемежаемые другими символами, такие, как ABC в AABBCC (в этой строке есть 4 возможные пары непересекающихся вхождений ABC: y1y3y5, y2y4y6; y1y3y6, y2y4y5; y1y4y5, y2y3y6; y1y4y6, y2y4y5). В общем случае, когда разрешены перемежаемые другими символами последовательности, и каждый символ максимальной повторяющейся подпоследовательности встречается в строке ровно два раза, в строке может быть до 21/2 пар непересекающихся вхождений максимальной подпоследовательности, что дает в худшем случае экспоненциальное число пар, так как l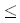 [n/2]. Когда символы подпоследовательности встречаются в строке более двух раз, потенциальное число пар еще больше. Следует учитывать также, что в строке может быть более одной максимальной повторяющейся подпоследовательности. Например, в строке PDEQFABCRSATBCDEUF ими являются ABC и DEF.
[n/2]. Когда символы подпоследовательности встречаются в строке более двух раз, потенциальное число пар еще больше. Следует учитывать также, что в строке может быть более одной максимальной повторяющейся подпоследовательности. Например, в строке PDEQFABCRSATBCDEUF ими являются ABC и DEF.
Метод отыскания отдельной пары вхождений максимальной повторяющейся подпоследовательности состоит в том, чтобы вычислить самую тяжелую общую подпоследовательность y с собой, с весом для сопоставления (i, j) равным 0, когда i равняется j, и 1 в противном случае. Как мы видели, это можно выполнить, используя метод динамического программирования, или алгоритм hcs Джекобсона и Во [Jacobson, Vo, 1992]. В первом случае требуется время O(n2), а во втором O((r+n) log n), где r – число сопоставлений.
Для иллюстрации этого метода ниже приведен весовой массив hcs метода динамического программирования для y = AABBCC. Массив генерируется с использованием отношением рекуррентности (4.58) и вышеуказанными весами сопоставлений.
Фактическая максимальная повторяющаяся подпоследовательность может затем быть восстановлена из массива обратным прослеживанием ее зависимостей, как в методе динамического программирования для вычисления расстояний редактирования между строками.
|
|
j | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| i |
|
|
A | A | B | B | C | C |
| 0 |
|
0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | A | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| 2 | A | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | B | 0 | 1 | 1 | 1 | 2 | 2 | 2 |
| 4 | B | 0 | 1 | 1 | 2 | 2 | 2 | 2 |
| 5 | C | 0 | 1 | 1 | 2 | 2 | 2 | 3 |
| 6 | C | 0 | 1 | 1 | 2 | 2 | 3 | 3 |
Обратите внимание, что нахождение максимальной повторяющейся подпоследовательности является, таким образом, эквивалентным нахождению максимального монотонно возрастающего пути в графе, составленного из узлов, соответствующих сопоставлениям (i, j), где yi = yj и i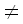 j. Это напоминает алгоритм lcs Ханта-Шиманского [Hunt, Szymanski, 1977], который, таким образом, можно преобразовать, чтобы выполнять задание за такое же асимптотическое время, что и при алгоритме hcs Джекобсона-Во. Пара таких путей, соответствующих отдельной паре вхождений максимальной повторяющейся подпоследовательности ABC в строке AABBCC показана ниже. Узлы, составляющие пару непересекающихся путей, представлены один закрашенными, а другой – пустыми кружками. Показанная ниже пара путей представляет пару вхождений y1y4y5 и y2y3y6.
j. Это напоминает алгоритм lcs Ханта-Шиманского [Hunt, Szymanski, 1977], который, таким образом, можно преобразовать, чтобы выполнять задание за такое же асимптотическое время, что и при алгоритме hcs Джекобсона-Во. Пара таких путей, соответствующих отдельной паре вхождений максимальной повторяющейся подпоследовательности ABC в строке AABBCC показана ниже. Узлы, составляющие пару непересекающихся путей, представлены один закрашенными, а другой – пустыми кружками. Показанная ниже пара путей представляет пару вхождений y1y4y5 и y2y3y6.
|
|
j |
1 |
2 |
3 |
4 |
5 |
6 |
|
i |
|
A |
A |
B |
B |
C |
C |
|
1 |
A |
|
· |
|
|
|
|
|
2 |
A |
° |
|
|
|
|
|
|
3 |
B |
|
|
|
° |
|
|
|
4 |
B |
|
|
· |
|
|
|
|
5 |
C |
|
|
|
|
|
· |
|
6 |
C |
|
|
|
|
° |
|
Таким образом, использование алгоритма lcs позволяет находить максимальную повторяющуюся подпоследовательность, причем этого можно достигнуть за время O((r+n) log n), используя метод Джекобсона-Во. Однако, следует заметить, что в общем случае нахождение всех возможных непересекающихся пар вхождений максимальных повторяющихся подпоследовательностей не является жизнеспособным предложением. Это эквивалентно перечислению всех возможных пар непересекающихся монотонно возрастающих путей в графе взвешенных сопоставлений. Как сообщалось ранее, это в худшем случае это является задачей экспоненциальной сложности.
Я обязан Дену Хиршбергу и Вонгу Во за предложенные ими методы решения задачи максимальной повторяющейся подпоследовательности. Кроме того, с большой благодарностью был принят вклад многих других респондентов Интернета, приславших множество литературных ссылок.
